
Medical students can’t help but plagiarize, apparently
I recently experienced some deja vu taking me back to my time in med school, which is never pleasant. It was the orientation week and we were basically taking some practice courses that would let us get to know each other and get used to how the actual courses would be. We were sitting at tables of about 9 people and listening to a lecture about unusual genetic disorders. The professor described a patient who had patches of albinism or something along those lines. This was obviously a case of a genetic chimera resulting from a mutation that occurred early during development.
I rarely answer questions in class so I had no intention of getting on the microphone and explaining this simple case. The reason for this is twofold. If I answered every question I could answer I would end up answering every single question and that would defeat the purpose of the professor even asking questions. Secondly, nothing good can come from letting a class know how smart you are. The only time I will answer a question is if I am called on or I think the question is particularly clever. But since this question was insulting to my intelligence I had no intention of answering it.
So after the professor asks a question the groups of students are supposed to talk amongst themselves and discuss what they think the answer is. Because this is the first week of school students are very eager to make a good first impression and establish themselves as one of the “smart” students. We had one such student at my table. He starts off telling our table that he majored in genetics so he knows what he’s talking about. Everyone at the table immediately looks upon him with awe and he tells us that he feels this is a case of epigenetics.
Now I don’t want to appear smart, but I also don’t want to appear stupid, and I didn’t want to be associated with a wrong answer for such a simple question. So I tell the group this is a classic example of a chimera. As soon as I say this the genetics major grabs the microphone and says that he thinks the patient is a chimera and the professor starts nodding his head. And then at the end he throws in “and maybe there’s some epigenetics”. He gets off the microphone and immediately winks at me. Da fuck? The professor says “I’m not sure about that last thing you said, but yes the patient is a chimera.”
Again, I never had any intention of answering such an easy question and didn’t care that someone took my answer. It would be like if I dropped a penny on the ground and someone picked it up and kept it. It doesn’t matter to me. All it did was show me that I should avoid this person. And if any intelligent person was paying attention his mention of epigenetics exposed him as a dumbass anyways.
Now to what triggered this deja vu. I stumbled upon this post at Retraction Watch where a physician apparently plagiarized a blog post, got caught, and then the journal refused to retract the paper. I’ve been falsely accused of plagiarism before so I’m not one to jump to conclusions when someone claims they should be cited. And there are so many people in the world that there is a chance for two people to independently have the same idea, but when you take the time to look at the facts of this case they start to become overwhelming.
The paper involves bitcoins, which I basically know nothing about, so I have no idea a priori how original the work is or how significant it is. However, as soon as you see the article things start to look fishy. First off, the paper is very short, and only has a single supplemental file. In fact, the paper is about the same length as the blog post it allegedly plagiarizes! And even if you don’t know anything about bitcoins or clinical trials you quickly see that the ideas in the two articles are basically identical all the way down to the hashing algorithm (SHA-256).
Okay, so perhaps Greg Irving the physician had this idea independently of Benjamin Carlisle the graduate student blogger, and the expression of that idea and length of the article just happened to be very similar. It’s possible. But when you start to look at some of the wording it’s not similar, it’s IDENTICAL. One phrase in particular, “a distributed, permanent, timestamped public ledger”, caught my eye. Maybe that is a typical way to describe blockchains, as claimed by Amy Price, one of the reviewers of the paper. I googled it. Nope. The only times the phrase shows up is in the blog and the paper. I even deleted some of the words, and the only hits were still the blog and the paper. And it turns out that the blog may not even be the only thing Greg Irving plagiarized. Neuroskeptic did an analysis that shows some text seems to paraphrase a Wall Street Journal article.
At this point it’s looking pretty damning, not only is the idea identical, but the text is as well, indicating that the authors clearly read the blog post and just reworded it and submitted it for publication. But it gets even worse. When you look at the methods of the article you realize that these people likely know nothing about bitcoins. Carlisle in his blog proposed using an unformatted text file. Irving in the article also describes using an unformatted text file. The problem? The file they provide is a Microsoft Word document. I’m not a computer scientist, but I do a lot of programming and know Word documents are definitely not “unformatted”. Look at what happens below when I try to read data from the file they provide:
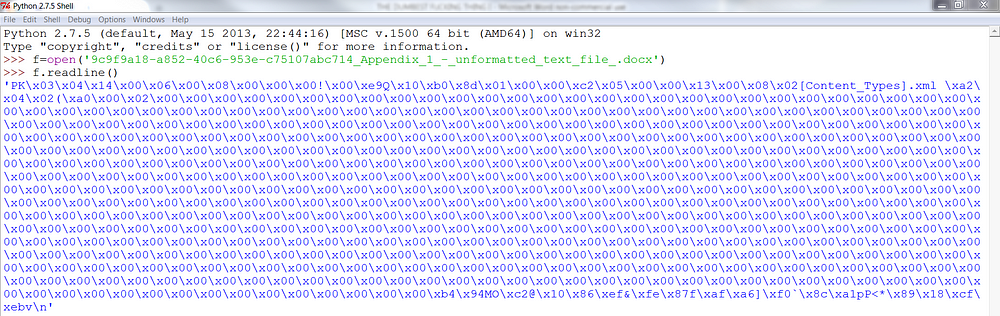 Does that look unformatted to you?
And to calculate the hash value they rely upon an online application, Xorbin. Now I’ve never needed to do any hashing before, but if I did I would use a programming language. If someone were an expert in bitcoins and had to constantly generate hash values you would also think they would use a programming language. Okay, maybe they just used the online application so that readers could easily use the method. That still doesn’t solve the problem of the file they provide. Look at what happens when I calculate the SHA-256 value of the file they provide versus the text copied into Notepad which I saved as “unformatted.txt”.
Does that look unformatted to you?
And to calculate the hash value they rely upon an online application, Xorbin. Now I’ve never needed to do any hashing before, but if I did I would use a programming language. If someone were an expert in bitcoins and had to constantly generate hash values you would also think they would use a programming language. Okay, maybe they just used the online application so that readers could easily use the method. That still doesn’t solve the problem of the file they provide. Look at what happens when I calculate the SHA-256 value of the file they provide versus the text copied into Notepad which I saved as “unformatted.txt”.
 The values are different just as we expected.
Now if I calculate the value by carefully pasting their table into Xorbin I do get the value of the unformatted file.
The values are different just as we expected.
Now if I calculate the value by carefully pasting their table into Xorbin I do get the value of the unformatted file.
 However, the use of a Word document and requiring users to manually paste the data seems dangerous and prone to errors. In fact, Retraction Watch interviewed a blockchain expert and he believes that using a Word document could cause problems. I myself have experienced problems sending Word documents between Mac and Windows machines where the line endings get messed up. Who knows what other problems may occur and affect the validity of the method.
All in all it paints a picture of a physician who knows nothing about programming or using bitcoins who stumbled upon Carlisle’s blog and thought he could get a quick publication out of it, just like the medical student who stole my answer and revealed himself by throwing in epigenetics into his answer. And when Carlisle confronted F1000Research Greg Irving could not have acted any guiltier. He revised the manuscript heavily citing the blog, rewording phrases which were word for word identical, and fully acknowledged that the idea was first proposed by Carlisle. He refused to comment for Retraction Watch, and deleted his Twitter account. He told Retraction Watch that he only wants to communicate “in the normal manner of academic dialogue”. Umm, does that mean I need to plagiarize someone’s work in any communication with him?
If I was accused of plagiarism I didn’t commit I would behave very differently. In fact, I’m currently working on something which someone may have already discovered. Hell, multiple people may have already discovered it. But as far as I can tell no one has turned it into a useful tool, which is going to require a lot of effort by me. So if someone claims they already thought of it I’m going to say too bad, you didn’t turn it into a useful tool which everyone can use. And if they still bother me I’m going to get lawyers involved.
In fact, this seems to be the rationale for why F1000Research decided to allow the paper to be published even after it was revealed it was plagiarized. Amy Price claims that the key is operationalizing the idea, which the paper did and the blog post didn’t. Umm, all the paper did was provide a text file which wasn’t even in the correct format and claim they calculated the hash and set up a bitcoin account. So, just to recap, the one thing the journal thinks makes this a valid paper is an error prone, possibly incorrect method. Those are some high standards; no wonder you have to have a PhD/MD to publish there.
Actually, I can’t blame F1000Research for allowing research like this to get published. As the creator and current maintainer of PrePubMed I index all of their articles and know how many articles get added each day to their journal. And it’s not much compared to the other servers I index. It’s clear they are thirsty for articles and as a result can’t be too choosy:
However, the use of a Word document and requiring users to manually paste the data seems dangerous and prone to errors. In fact, Retraction Watch interviewed a blockchain expert and he believes that using a Word document could cause problems. I myself have experienced problems sending Word documents between Mac and Windows machines where the line endings get messed up. Who knows what other problems may occur and affect the validity of the method.
All in all it paints a picture of a physician who knows nothing about programming or using bitcoins who stumbled upon Carlisle’s blog and thought he could get a quick publication out of it, just like the medical student who stole my answer and revealed himself by throwing in epigenetics into his answer. And when Carlisle confronted F1000Research Greg Irving could not have acted any guiltier. He revised the manuscript heavily citing the blog, rewording phrases which were word for word identical, and fully acknowledged that the idea was first proposed by Carlisle. He refused to comment for Retraction Watch, and deleted his Twitter account. He told Retraction Watch that he only wants to communicate “in the normal manner of academic dialogue”. Umm, does that mean I need to plagiarize someone’s work in any communication with him?
If I was accused of plagiarism I didn’t commit I would behave very differently. In fact, I’m currently working on something which someone may have already discovered. Hell, multiple people may have already discovered it. But as far as I can tell no one has turned it into a useful tool, which is going to require a lot of effort by me. So if someone claims they already thought of it I’m going to say too bad, you didn’t turn it into a useful tool which everyone can use. And if they still bother me I’m going to get lawyers involved.
In fact, this seems to be the rationale for why F1000Research decided to allow the paper to be published even after it was revealed it was plagiarized. Amy Price claims that the key is operationalizing the idea, which the paper did and the blog post didn’t. Umm, all the paper did was provide a text file which wasn’t even in the correct format and claim they calculated the hash and set up a bitcoin account. So, just to recap, the one thing the journal thinks makes this a valid paper is an error prone, possibly incorrect method. Those are some high standards; no wonder you have to have a PhD/MD to publish there.
Actually, I can’t blame F1000Research for allowing research like this to get published. As the creator and current maintainer of PrePubMed I index all of their articles and know how many articles get added each day to their journal. And it’s not much compared to the other servers I index. It’s clear they are thirsty for articles and as a result can’t be too choosy:
 When something like this happens it’s easy to just write a blog post or make an anonymous comment somewhere. Well I am so confident that injustice was done that I decided to put my money where my mouth is and make a comment on PubMed attaching my name to my conclusions.
When something like this happens it’s easy to just write a blog post or make an anonymous comment somewhere. Well I am so confident that injustice was done that I decided to put my money where my mouth is and make a comment on PubMed attaching my name to my conclusions.
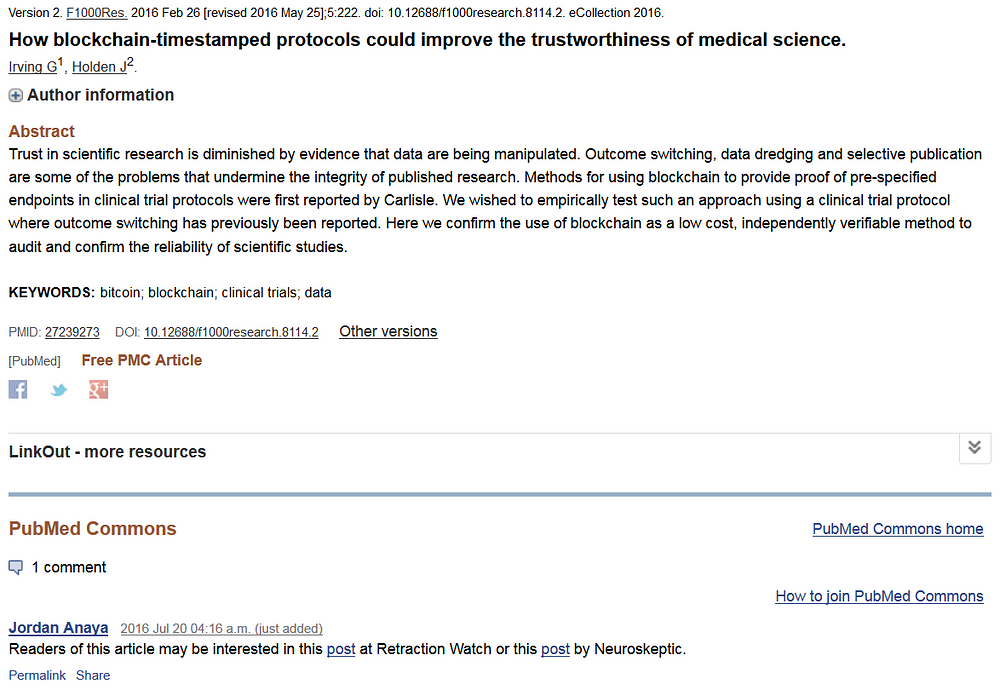 P.S. It also helps that I’m no longer in academia and couldn’t give a fuck if I upset anyone.
P.S. It also helps that I’m no longer in academia and couldn’t give a fuck if I upset anyone.
If you would like to comment on this post it is available at Medium